海量调用背后的突围:国产AI模型如何从边缘走向全球舞台
你有没有想过,当你在敲下一行代码或者询问AI一个问题时,后台运行的那个模型,可能正来自数千公里外的中国实验室?最近,一组数据在科技圈炸开了锅:国产大模型连续三周在调用量上压过美国模型一头。这背后,是一个关于追赶、挣扎与最终突围的漫长故事。
回想几年前,国产AI还处于“摸着石头过河”的阶段。那时候,我们常常听到这样的质疑声:“国产模型行不行?”“是不是只能复现国外的架构?”这种焦虑不仅仅存在于公众的认知里,更真实地压在每一位国产模型研发者的心头。他们每天面对的,是算力紧缺的现实,是算法调优的枯燥,以及在国际巨头垄断下的生存压力。
从被动追赶到主动突围
那段日子里,研发团队的每一个深夜几乎都在与代码和报错作斗争。为了提升那几个点的精度,为了让模型在特定场景下跑得更稳,团队成员经历了无数次推倒重来。最难的时候,甚至有人怀疑过方向是否正确。然而,正是这种不服输的劲头,让他们在开源领域找到了突破口。他们意识到,如果无法在闭源的高墙内与巨头硬碰硬,那就把技术的大门打开,让世界看到国产模型的潜力。
这种“开源”策略,就像是在荒原上种下了一片森林。国产模型开始被全球开发者接纳、下载、微调。当海外工具被发现“套壳”国产模型时,那不仅是一个尴尬的乌龙,更是一种迟来的认可——国产模型,真的好用。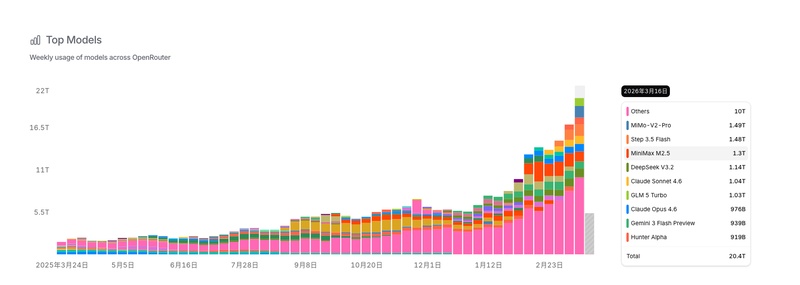
成长路上的关键转折
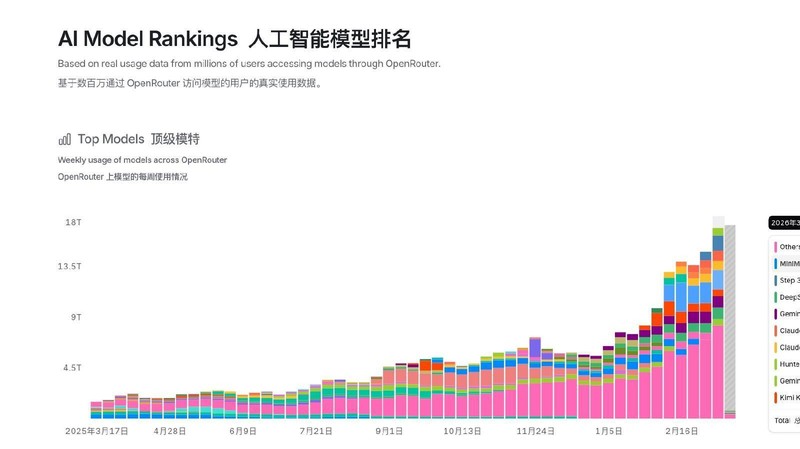
突破时刻,往往伴随着对自我的重新定义。当国产模型不再仅仅追求“大”,而是追求“快”、“准”与“好用”时,全球用户的反馈给了最直接的答案。调用量连续三周领先,这不仅是一个数字,更是无数开发者在用脚投票。
你可能会问,这种增长能持续吗?答案或许藏在开源与闭源的共生关系中。黄仁勋曾说过,开源与闭源是“AND”的关系。国产模型不仅是在竞争,更是在构建一个兼容并包的生态。现在的每一行代码,每一次调用,都在为未来的AI时代铺路。我们正在见证的,是一个从单一技术追随者,转变为全球AI基础设施建设者的伟大历程。