AI帮你干活,却说不清干得怎么样?这款工具让机器学会交“结项报告”
你有没有过这样的经历:让AI帮你处理一件事,它啪嗒啪嗒操作完,然后告诉你"搞定了"。你一看结果,好像没问题,但仔细想想,又总觉得哪里不对劲——它真的做对了吗?有没有遗漏什么?
说实话,这种"心里没底"的感觉,挺让人焦虑的。毕竟AI再智能,终究不是人,它不会主动告诉你"这个步骤我多检查了两遍"或者"那个设置我特意确认了三遍"。你只能靠自己去核对,而核对这件事,有时候比让AI干活还要累。
为什么验证比执行更难?
做技术的朋友可能更清楚这背后的苦衷。在LLM/VLM驱动的智能体领域,有个特别尴尬的问题:你让AI去操作一个App,它可能十秒钟就搞定了,但验证它有没有做对,却需要花上好几倍的时间。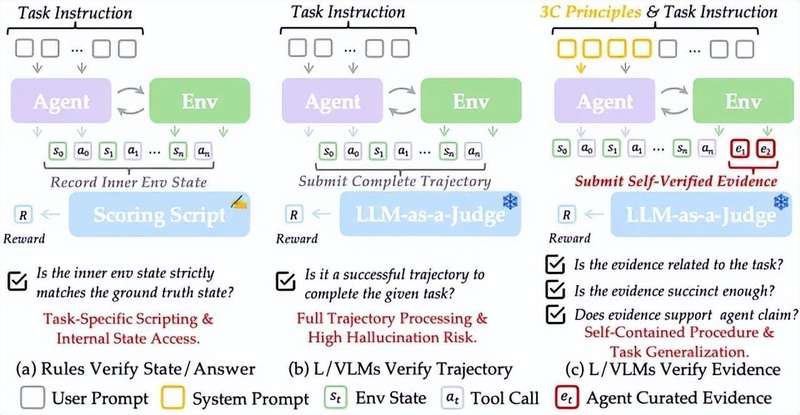
传统的解决办法是给AI配一个"裁判"。裁判盯着AI的每一步操作,然后判断它做得对不对。这个思路没问题,但实际操作起来,麻烦就来了——裁判需要预先知道所有正确的状态变化,这意味着一旦换了个新环境,裁判的规则就得重新写。更要命的是,AI的操作轨迹可能很长,裁判要在一堆环境噪声里找到关键信息,这本身就是个技术活。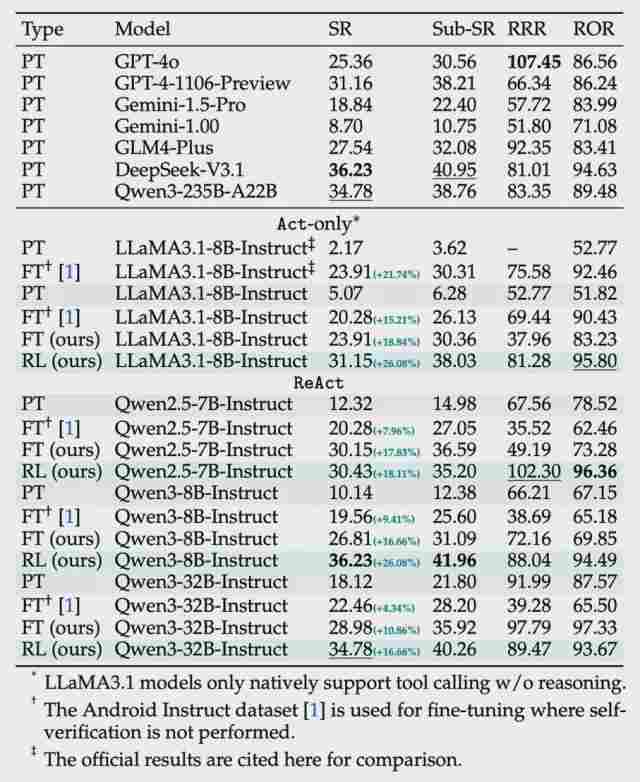
有时候环境本身也会"叛变"——页面突然刷新,刚才的操作信息就丢了,裁判只能无奈地判定"操作失败",尽管AI其实已经做对了。
一个转念:与其让裁判更聪明,不如让AI学会自证
SmartSnap这个项目提出了一个特别有意思的思路:与其不断完善外部验证系统,不如让AI自己学会证明自己。
具体怎么做到呢?简单来说,SmartSnap让AI在执行任务的同时,主动收集"证据快照"。就像你做完工作后,需要提交一份结项报告一样,AI也需要提交它的"结项报告"——只不过这份报告不是文档,而是一组关键的截图。
比如,AI帮你修改了某个设置,它会自动把这个设置的状态截图下来,作为"证据"提交。这样你一看截图,就知道"哦,确实改好了"。整个过程不需要任何外部裁判介入,AI自己就把验证的事儿给办了。
三招打造高质量证据链
你可能会问:AI收集证据会不会用力过猛,搞出一大堆截图让人看不过来?SmartSnap早就想到了这一点,他们提出了一个"3C原则"来约束AI的证据收集行为。
第一条叫"完整性"。AI收集的证据必须足以证明任务完成了,不能让验证者看了截图还有疑问。第二条叫"简洁性",强调证据不在多而在精,几个关键瞬间的定格就够了,不用搞个长视频让人慢慢看。第三条最有意思,叫"创造性"——允许AI为了获取证据而做一些"额外操作"。比如订完机票后,AI会主动跳回订单页截个图,而不是让验证者自己去找订单记录。
这三条原则听起来简单,但真正落地却需要精细的算法设计。SmartSnap团队用GRPO算法配合精心设计的奖励机制,教会AI在"完成任务"和"证明任务完成"之间找到平衡。
实战效果:小模型也能打大仗
说了这么多,你肯定关心实际效果怎么样。实验数据显示,SmartSnap在不同规模的模型上都实现了显著的性能提升,最高提升幅度达到26.08%。更让人惊喜的是,经过训练的中等参数模型(比如Qwen3-32B),在证据能力的加持下,表现竟然能和那些"参数量是它七八倍"的大模型相媲美。
还有个数字特别打动我:平均每个任务只需要1.5张快照证据。这意味着验证成本被压缩到了极致。以前可能需要盯着AI操作好几分钟才能确认结果,现在看一两张截图就够了。
当然,这套方案也有它的局限性。在某些专业领域(比如地图应用的复杂路径规划),AI还是会出现"知识跟不上"的问题,导致反复尝试却收效甚微。这提醒我们,证据能力终究不能替代真正的领域知识。
从"能干活"到"可信赖"
回过头来看,SmartSnap最有价值的地方,不在于它解决了某个具体的技术问题,而在于它提出了一种新的思维方式:未来的AI,不仅要能干,更要可信。
这种可信不是靠外部的层层审计实现的,而是AI自己主动交付的。当AI学会主动收集证据、学会用证据说话,我们和AI之间的信任关系就会发生根本性的改变——从"我猜你做对了",变成"你用证据证明你做对了"。
这或许就是AI走向大规模落地的必经之路。如果你也在为"AI干活靠不靠谱"这件事发愁,不妨关注一下这个项目。说不定它能给你一些新的启发。
想深入了解技术细节的朋友,可以去读读这篇论文:https://arxiv.org/abs/2512.22322,代码也已经开源在:https://github.com/TencentYoutuResearch/SmartSnap。